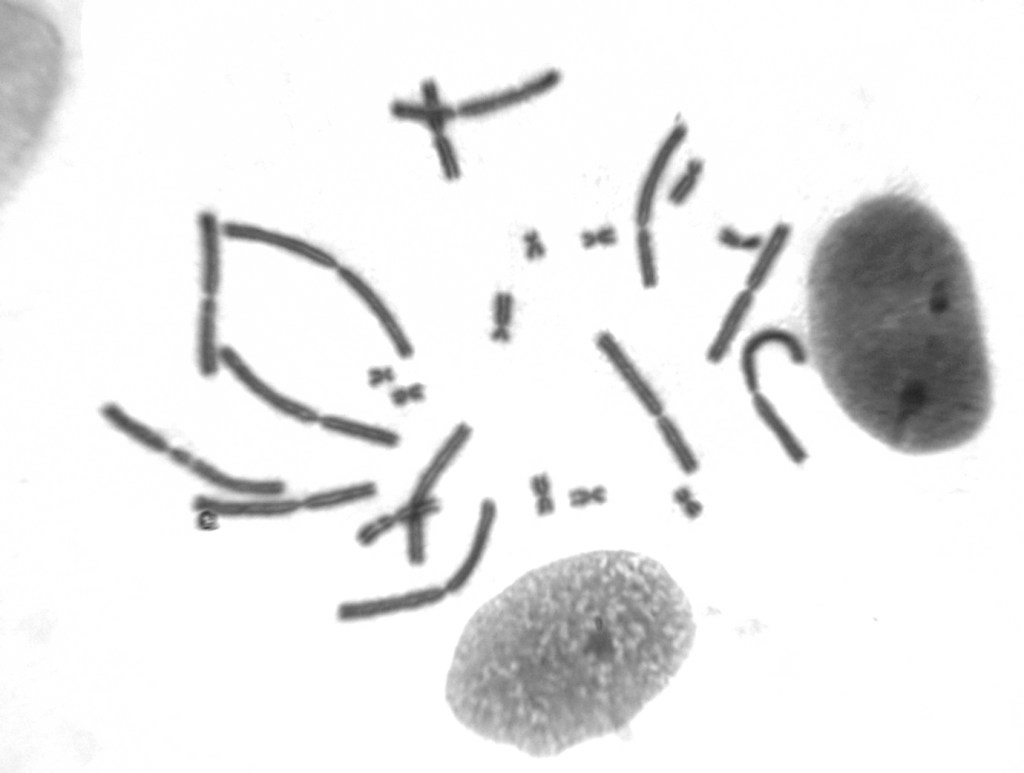
The first step of the ENDEMIXIT project was to produce genomic resources for the five Italian endemic species, including de novo reference genomes and resequencing data for large and small populations. The reference genomes are currently at different stages owing to the diverse genome sizes, ploidy, heterozygosity, and available data. The de novo sequences were obtained by combining diverse sequencing strategies including Illumina, PacBio and Omni-C. The bear reference genome assembly is almost ready and at the annotation stage. The butterfly transcriptome is complete (see the post: The Hipparchia sbordonii transcriptome is done! 21.01.2021 post) while the corresponding reference genome, yet the smallest one among the five species, has posed several challenges due to the high heterozygosity but we are close to the first draft. We excluded contaminations and observed a good integrity and genetic representation (further details in the next posts). The UniFi cytogenetic lab is working on the toad chromosomes’ microdissection; these chromosomes will be individually sequenced on an Illumina platform and used to guide de novo assembly of PacBio reads (see the figure below). In the next months, we expect to receive the PacBio, Bionano and Hi-C data from VGP (Vertebrate Genome Project) to proceed with the lizard and sturgeon de novo assemblies. The Illumina resequencing data are all already available (see the post: Here comes the data! 06.05.2021).